TOC
前言
docker 默认的日志驱动是json-file,每一个容器都会在本地生成一个/var/lib/docker/containers/containerID/containerID-json.log,而日志驱动是支持扩展的,本章主要讲解的是 Fluentd 驱动收集 docker 日志.
Fluentd 是用于统一日志记录层的开源数据收集器,是继 Kubernetes、Prometheus、Envoy 、CoreDNS 和 Containerd 后的第6个 CNCF 毕业项目,常用来对比的是 elasticsearch 的 logstash,相对而言 fluentd 更加轻量灵活,现在发展非常迅速社区很活跃,在编写这篇 blog 的时候 github 的 star 是8.8k,fork 是 1k 就可见一斑.
前提
准备配置文件
docker-compose.yml
version: '3.7'
x-logging:
&default-logging
driver: fluentd
options:
fluentd-address: localhost:24224
fluentd-async-connect: 'true'
mode: non-blocking
max-buffer-size: 4m
tag: "kafeidou.{{.Name}}" #配置容器的tag,以kafeidou.为前缀,容器名称为后缀,docker-compose会给容器添加副本后缀,如 fluentd_1
services:
fluentd:
image: fluent/fluentd:v1.3.2
ports:
- 24224:24224
volumes:
- ./:/fluentd/etc
- /var/log/fluentd:/var/log/fluentd
environment:
- FLUENTD_CONF=fluentd.conf
fluentd-worker:
image: fluent/fluentd:v1.3.2
depends_on:
- fluentd
logging: *default-logging
fluentd.conf
<source>
@type forward
port 24224
bind 0.0.0.0
</source>
<match kafeidou.*>
@type file
path /var/log/fluentd/kafeidou/${tag[1]}
append true
<format>
@type single_value
message_key log
</format>
<buffer tag,time>
@type file
timekey 1d
timekey_wait 10m
flush_mode interval
flush_interval 5s
</buffer>
</match>
<match **>
@type file
path /var/log/fluentd/${tag}
append true
<format>
@type single_value
message_key log
</format>
<buffer tag,time>
@type file
timekey 1d
timekey_wait 10m
flush_mode interval
flush_interval 5s
</buffer>
</match>
由于 fluentd 需要在配置的目录中有写入的权限,所以需要先准备好存放 log 的目录以及给予权限.
创建目录
mkdir /var/log/fluentd
给予权限,这里用于实验演示,直接授权 777
chmod -R 777 /var/log/fluentd
在 docker-compose.yml 和 fluentd.conf 的目录中执行命令:
shell docker-compose up -d
[root@master log]# docker-compose up -d
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Creating network "log_default" with the default driver
Creating fluentd ... done
Creating fluentd-worker ... done
查看一下日志目录下,应该就有对应的容器日志文件了:
[root@master log]# ls /var/log/fluentd/kafeidou/
fluentd-worker.20200215.log ${tag[1]}
这是我最后的一个实验结果,会创建一个${tag[1]}目录,挺奇怪的,而且在这个目录下还会有两个文件
[root@master log]# ls /var/log/fluentd/kafeidou/\$\{tag\[1\]\}/
buffer.b59ea0804f0c1f8b6206cf76aacf52fb0.log buffer.b59ea0804f0c1f8b6206cf76aacf52fb0.log.meta
如果有明白这块的也欢迎一起交流!
架构总结
为什么不用 docker 的原始日志呢?
我们先看一下原始的 docker 日志是怎么样一个架构:

docker会在本机的/var/lib/docker/containers/containerID/containerID-json.log路径为每一个容器生成一个 log 文件,存储 Docker 的日志.
上图中总共有 7 个容器,当成 7 个微服务的话,在需要查看日志的时候就已经很不方便了,最差情况需要分别在三台机器上查看每一个容器的日志.
使用了fluentd后有什么不一样?
使用 fluentd 收集 Docker 日志后可以将容器汇总到一起.来看看配置了本文的 fluentd 配置文件后的架构:
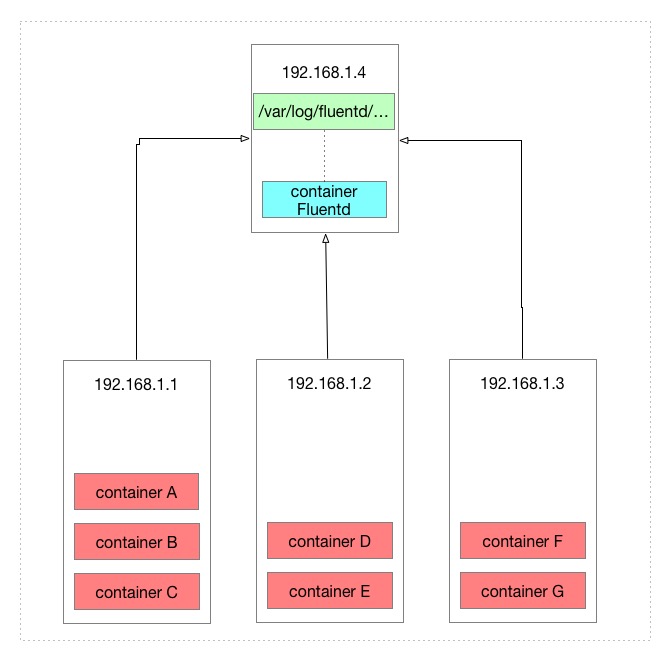
由于 fluentd 配置的是存储在 fluentd 所在机器的本地目录,所以效果是将其他机器的容器日志收集到 fluentd 所在机器的本地目录中.
fluentd只能将容器日志收集到本地吗?
fluentd 实际上可以将收集到的日志再次传输出去,例如传输到 elasticsearch 等存储软件中:
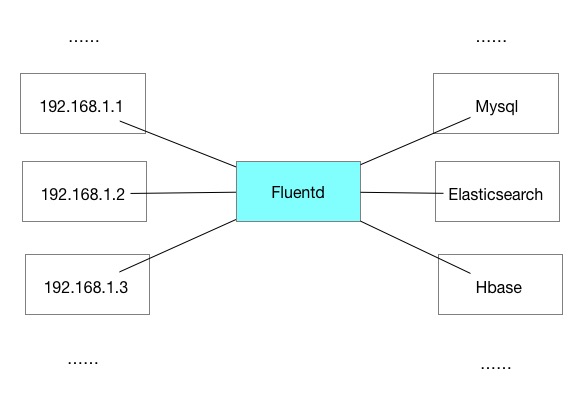
fluentd灵活性
fluentd 能做的事情还有很多,fluentd 本身能作为传输节点也能作为接受节点,还能够过滤特定日志,格式化特定内容的日志,将匹配的特定日志再次传输出去,这里只是做到一个简单的收集 docker 容器日志的效果.
微信公众号
扫描下面的二维码关注我们的微信公众号,第一时间查看最新内容。同时也可以关注我的Github,看看我都在了解什么技术,在页面底部可以找到我的Github。